Table of Contents
This post will highlight the basics of BigQuery and how to read, write and administer your BigQuery dataset in a Java application.
BigQuery is a managed data warehouse, and is part of the Google Cloud Platform. We can use the official Java client to interact with our datasets.
If you just want to see the example code, you can view it on Github
BigQuery Jobs
Every operation on a BigQuery dataset can be described in terms of a job.
When you want to run a query or transfer data from one dataset to another, you send a job description to your BigQuery instance, and it is executed as a job to get the final result.

In BigQuery, an SQL query is run as a job. In this post, “running a query” is the same as “executing a job”
Creating a New Service Account
To enable your Java application to execute jobs on BigQuery, it requires a service account.
Ideally, each application has its own service account. Service accounts let BigQuery know that an application is trusted and can run jobs on it.
To create a service account, go to the service accounts page and click on “CREATE SERVICE ACCOUNT”.
In the creation page, we need to provide a name, and give the “BigQuery Admin” role:
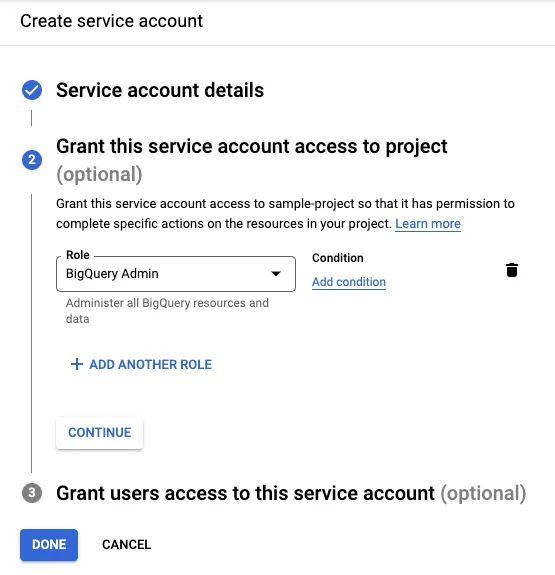
Now we can create a key by going into the “Keys” tab of the service account we created:
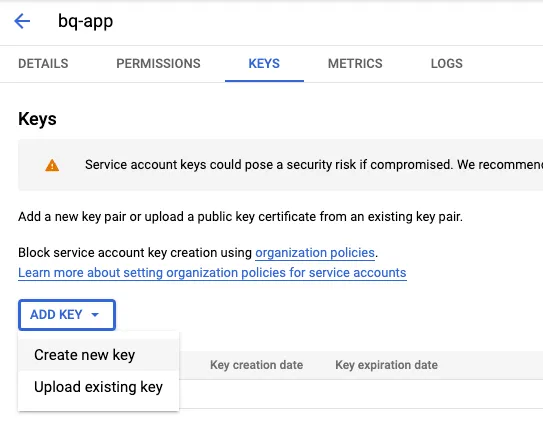
You should be able to download this key as a JSON file. We will be using this in our Java application later.
Setting Up a New Java Application
Let’s create a new Maven Java application. Our folder structure should look like this:
.
├── pom.xml
└── src
├── main
│ └── java
│ └── com
│ └── sohamkamani
│ └── App.java
└── test
└── java
└── com
└── sohamkamani
└── AppTest.javaQuerying Data From an Existing Table
Let’s take a look at the code to get data from an existing table.
For this example, we’re going to get the top 10 most used words in Shakespeare’s “Julius Caesar”, using the public shakespeare dataset.
Our program will run in 4 steps:
- Initialize the BigQuery service
- Create a job to run our query
- Run the job on BigQuery and check for errors
- Display the result
We can add the following code to the App.java file:
public class App {
public static void main(String... args) throws Exception {
// Step 1: Initialize BigQuery service
// Here we set our project ID and get the `BigQuery` service object
// this is the interface to our BigQuery instance that
// we use to execute jobs on
BigQuery bigquery = BigQueryOptions.newBuilder().setProjectId("sample-project-330313")
.build().getService();
// Step 2: Prepare query job
// A "QueryJob" is a type of job that executes SQL queries
// we create a new job configuration from our SQL query and
final String GET_WORD_COUNT =
"SELECT word, word_count FROM `bigquery-public-data.samples.shakespeare` WHERE corpus='juliuscaesar' ORDER BY word_count DESC limit 10;";
QueryJobConfiguration queryConfig =
QueryJobConfiguration.newBuilder(GET_WORD_COUNT).build();
// Step 3: Run the job on BigQuery
// create a `Job` instance from the job configuration using the BigQuery service
// the job starts executing once the `create` method executes
Job queryJob = bigquery.create(JobInfo.newBuilder(queryConfig).build());
queryJob = queryJob.waitFor();
// the waitFor method blocks until the job completes
// and returns `null` if the job doesn't exist anymore
if (queryJob == null) {
throw new Exception("job no longer exists");
}
// once the job is done, check if any error occured
if (queryJob.getStatus().getError() != null) {
throw new Exception(queryJob.getStatus().getError().toString());
}
// Step 4: Display results
// Print out a header line, and iterate through the
// query results to print each result in a new line
System.out.println("word\tword_count");
TableResult result = queryJob.getQueryResults();
for (FieldValueList row : result.iterateAll()) {
// We can use the `get` method along with the column
// name to get the corresponding row entry
String word = row.get("word").getStringValue();
int wordCount = row.get("word_count").getNumericValue().intValue();
System.out.printf("%s\t%d\n", word, wordCount);
}
}
}To run this program, we need the location of the JSON file we downloaded when creating a service account.
We can then run our program by running this command:
GOOGLE_APPLICATION_CREDENTIALS=~/Downloads/your-service-account-file.json mvn exec:java \
-Dexec.mainClass="com.sohamkamani.App" -Dexec.classpathScope=runtimeChange the
mainClassargument based on your folder structure and package name inApp.java
This should give you the following result:
word word_count
I 521
the 520
and 431
to 380
of 350
you 344
not 248
BRUTUS 235
a 230
is 229It’s funny how the only non-filler word here is Brutus :)
Creating a New Table
To create your own table, go to the BigQuery console and create a new dataset under your project, if you haven’t already:
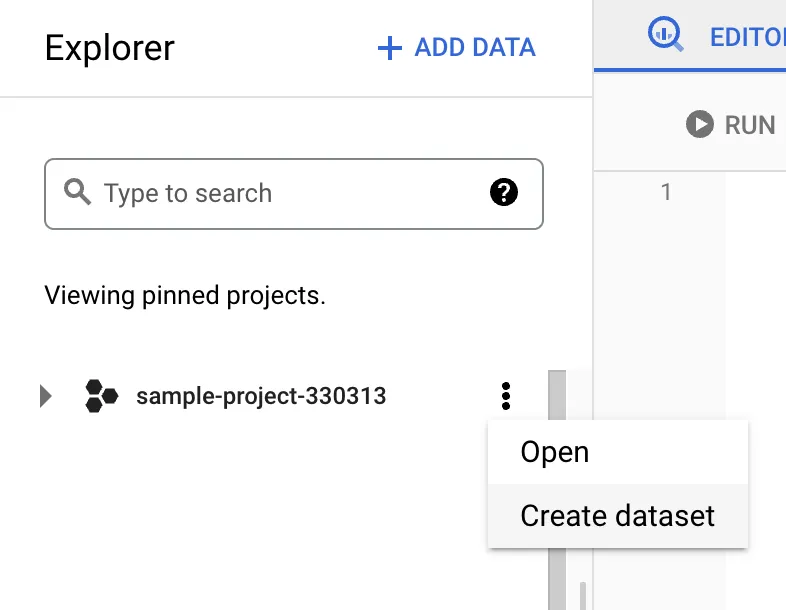
You’ll have to choose an ID for your dataset. For this example we’ll use sample_dataset as the dataset ID.
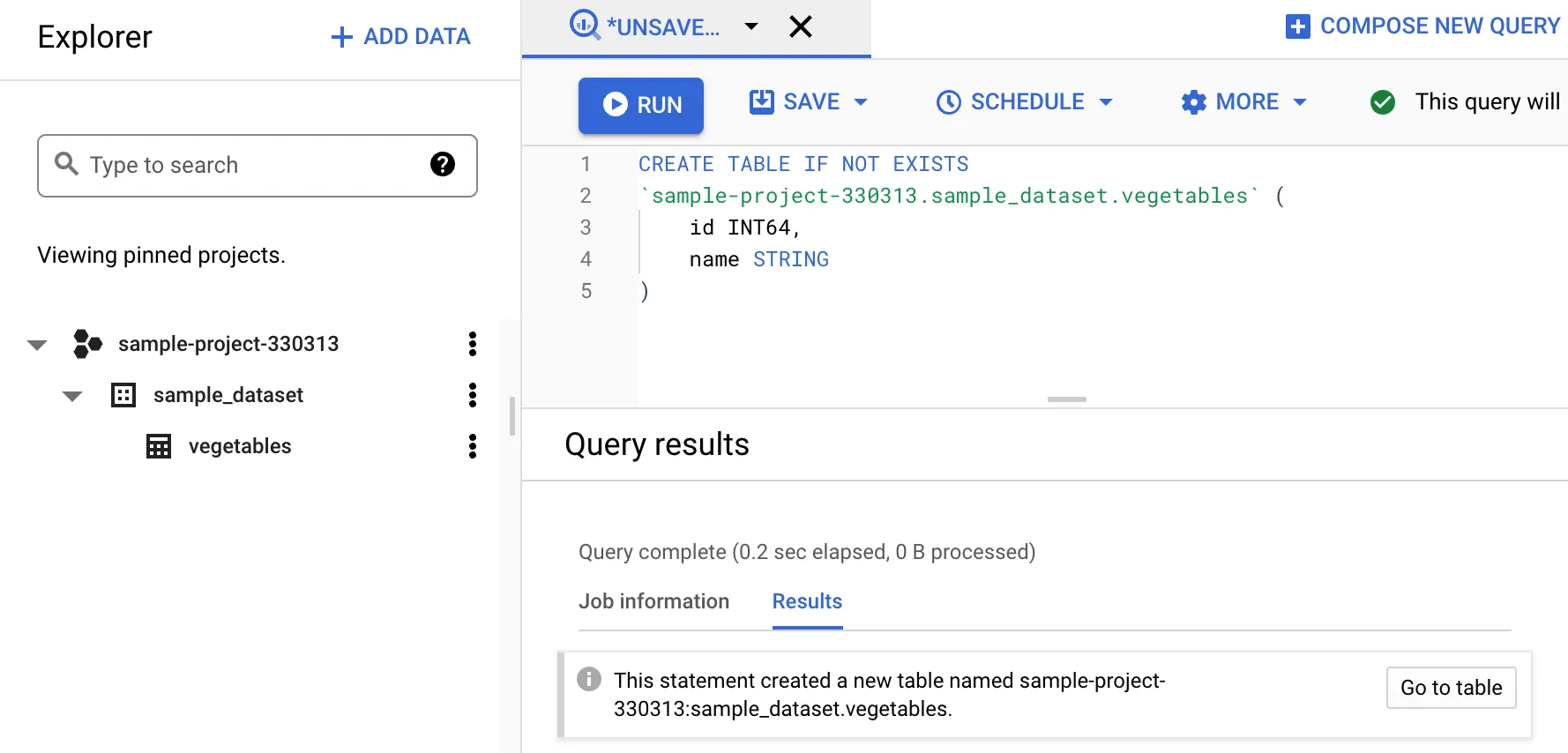
You can then run a CREATE TABLE query on the console. For example, let’s create a vegetables with an id and name field for each row:
CREATE TABLE IF NOT EXISTS `sample-project-330313.sample_dataset.vegetables` (
id INT64,
name STRING
)This will create a new vegetables table under the dataset sample_dataset:
Inserting Data With Queries
Note: In order to insert data into a BigQuery table, you’ll need to enable billing for your project.
We can insert data using queries, similar to how data is inserted in other relational databases.
Here, instead of a SELECT query, we will run an INSERT query, and instead of printing the resultant rows, we will print the number of rows inserted:
public class App {
public static void main(String... args) throws Exception {
// Step 1: Initialize BigQuery service
BigQuery bigquery = BigQueryOptions.newBuilder().setProjectId("sample-project-330313")
.build().getService();
// Step 2: Prepare query job
final String INSERT_VEGETABLES =
"INSERT INTO `sample-project-330313.sample_dataset.vegetables` (id, name) VALUES (1, 'carrot'), (2, 'beans');";
QueryJobConfiguration queryConfig =
QueryJobConfiguration.newBuilder(INSERT_VEGETABLES).build();
// Step 3: Run the job on BigQuery
Job queryJob = bigquery.create(JobInfo.newBuilder(queryConfig).build());
queryJob = queryJob.waitFor();
if (queryJob == null) {
throw new Exception("job no longer exists");
}
// once the job is done, check if any error occured
if (queryJob.getStatus().getError() != null) {
throw new Exception(queryJob.getStatus().getError().toString());
}
// Step 4: Display results
// Here, we will print the total number of rows that were inserted
JobStatistics.QueryStatistics stats = queryJob.getStatistics();
Long rowsInserted = stats.getDmlStats().getInsertedRowCount();
System.out.printf("%d rows inserted\n", rowsInserted);
}
}Inserting Streaming Data
Another way to insert data into your table is through a process called “streaming”.
When you insert data via queries, you need to create a job. Streaming enables you to move your data directly from your application into your BigQuery datastore, avoiding the overhead of creating a new job.
Instead of using a query, we need to define a map, with the row names as the keys, and the row values as the values. Each map represents a row, and multiple rows are wrapped in a request and sent by the client to the BigQuery instance:
Let’s see how to insert the same sample data using streaming:
public class App {
public static void main(String... args) {
// Step 1: Initialize BigQuery service
BigQuery bigquery = BigQueryOptions.newBuilder().setProjectId("sample-project-330313")
.build().getService();
// Step 2: Create insertAll (streaming) request
InsertAllRequest insertAllRequest = getInsertRequest();
// Step 3: Insert data into table
InsertAllResponse response = bigquery.insertAll(insertAllRequest);
// Step 4: Check for errors and print results
if (response.hasErrors()) {
// Here, each entry, or row, can have an error when we attempt to insert it
// Since we're attempting to insert multiple rows, we would have multiple
// errors we have to iterate through
for (Map.Entry<Long, List<BigQueryError>> entry : response.getInsertErrors()
.entrySet()) {
System.out.printf("error in entry %d: %s", entry.getKey(),
entry.getValue().toString());
}
return;
}
System.out.println("inserted successfully");
}
// To create a streaming insert request, we need to specify the table and dataset id
// and create the rows we want to insert
private static InsertAllRequest getInsertRequest() {
String datasetId = "sample_dataset";
String tableId = "vegetables";
return InsertAllRequest.newBuilder(datasetId, tableId).addRow(getRow(1, "carrot"))
.addRow(getRow(2, "beans")).build();
}
// each row is a map with the row name as the key and row value as the value
// since the value type is "Object" it can take any arbitrary type, based on
// the datatype of the row defined on BigQuery
private static Map<String, Object> getRow(int id, String vegetableName) {
Map<String, Object> rowMap = new HashMap<String, Object>();
rowMap.put("id", id);
rowMap.put("name", vegetableName);
return rowMap;
}
}If you want to know the details of what happens to your data during this process, you can read about the life of a BigQuery streaming insert.
Further Reading
BigQuery is a great tool for data analytics. Using the Java API, we can run any operation on our BigQuery instance within our Java application. You can also deploy your Java application on App Engine to access it from a public URL.
This gives us a lot of power and flexibility, and enables us to automate common operations on BigQuery, or even use BigQuery to power a production application.
You can read the complete code for all the examples here on Github.
If you want to read more about the Java API, you can see the official API documentation.