Web Security Basics - An Introduction to the Essential Concepts Behind a Secure Website
Table of Contents
This post is going to teach you everything you need to know about keeping your web application secure. The concepts that are highlighted in this post are essential for any web developer looking to make robust and secure websites.
Making a website that is secure is hard, but extremely important. I wrote this post because resources on this subject are scattered and not explained well enough for newcomers to understand.
The concepts highlighted here should help you understand the fundamentals of common issues and attacks that web applications can face on the internet, and how to fix them.
Sessions and Cookies
Irrespective of what type of website you’re making, if authentication is involved, you’ll encounter sessions and cookies.
Every website receives multiple requests from multiple different users. The key problem we’re trying to solve here is: How does the web server know which user is sending each request?
One option is to send information about the user to the browser just as they login. The browser will then store this information, and send it along with every subsequent request so that the server knows where it’s coming from.
The problem with this is that it isn’t secure. Any other browser (perhaps one that the user logged into previously) could also make a request with with this id and compromise the users security.

We need something more temporary.
Session Tokens
It is in our best interest to give as little information about the user to the browser as possible. So, instead of returning identifying information about the authenticated user, we instead return a piece of data called the “session token”.
A “session” is a single interval of time in which the user is authenticated.
What makes this secure is that each session comes with a different session token, and the session token by itself gives no indication about the identity of the logged-in user.
Now, each time John makes a request from their browser, they sends their current session token along with the request.
The server stores information about which session token maps to which user. Once the user logs out (or logs in again), or after a specified period of time, a new session token is generated and assigned, while the old token expires.

In the above picture “Browser 2” is where John previously logged in from. The token for that session was w344e3 , which has now expired. Once John logs out from “Browser 1”, their current session token (a23ww2) expires as well.
There is no way for any 3rd party to guess which session maps to which user since that information is stored safely on the server and is not made public.
The complication now is: The user always has to mention their session token with every request they make.
This means that anyone developing the client side code has to make sure to attach the session cookie with every request. Fortunately, browsers have an in-built way to attach this information with every request:
Session Cookies
In a nutshell, a cookie is a small piece of data kept with the browser, which (if the request comes from the same domain) is sent with every request automatically.
In our case, the cookie would be set to the value of session token (since that’s all that the server really needs). The exchange between the browser and the server would be the same as before, except the request from the browser would contain the session token every time.
In addition to their convenience, cookies can also be configured with additional properties, such as:
- Expiry time - Cookies can be automatically deleted after a certain time period.
- Javascript visibility - You can decide whether a cookie is visible from the javascript code running on the webpage
- Cross site visibility - Cookies can be restricted to only be sent to the domain by which they were created.
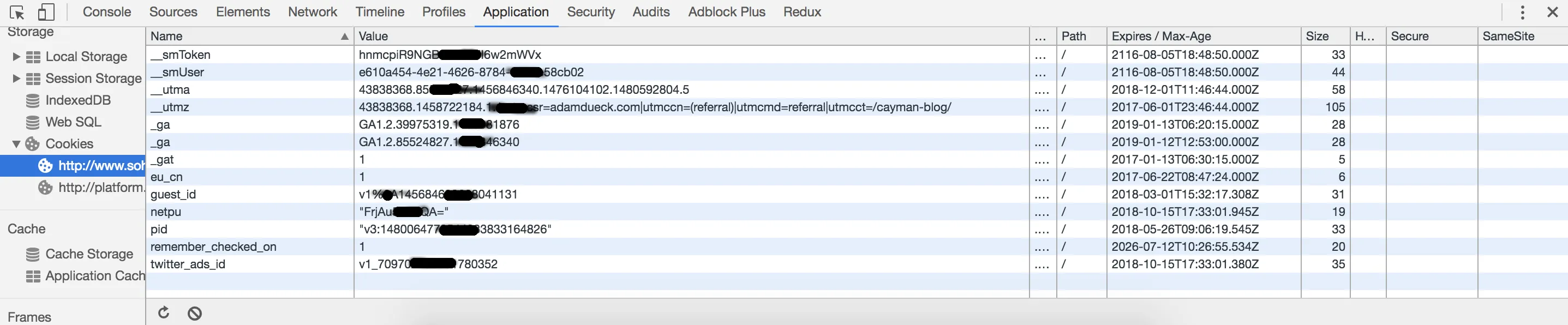
If you want to see the cookies currently stored for the current website you are visiting (like this one) right click anywhere on the page and click on “inspect” to open the developer tools (if you are on chrome). Next, go to the application tab and click on the cookies section under that.
Password Storage
Storing your users passwords is a huge responsibility. If you don’t do this correctly, you can compromise your entire application.
Let’s go through some methods used to store passwords, and come up with an acceptable solution for storing passwords in production.
Plain Text Storage
The first question many newcomers ask is: “Why can’t I just store the password like any other data?”
To answer this question, consider a database table containing username and password columns, with passwords stored like this :
| username | password |
|---|---|
| john | myawesomepassword |
The problem : This is very insecure. Something as simple as a system administrator keeping their laptop open by mistake could lead to your users passwords being compromised.
Note: If any website you go to emails you your actual password in case you forgot it, they probably store your password this way. You should run away, and fast.
Encryption
Ok, so maybe storing a password directly isn’t such a good idea. Lets try giving it some form of encryption to make it a little more secure.
As an example, let’s replace every letter of the password with the next letter in the alphabet.
| username | password |
|---|---|
| john | nzbxftpnfqbttxpse |
Now even if someone looks at this table they wouldn’t know the actual password. And if we want to log someone in, all we have to do is unencrypt this password and compare it with the password entered by the user on login.
The problem : There is still someone who has knowledge of the passwords in the system. In our case, we know that the password is formed by incrementing each letter to the next, so retrieving a users password is entirely possible for us.
As long as anyone can find out a users password, the system is never truly secure. You could come up with an algorithm as complex as you’d like, but as long as it’s reversible, its as easy to crack as this one.
One Way Hashing
Instead of using a reversible encryption algorithm, you could use an established hashing algorithm like md5 or sha-1. These hashing algorithms cannot be reversed in theory.
This means that just because we know the md5 hash of a word, doesn’t mean we can find out what that word is if we only have its md5 hash.
Lets revise our table to include the md5 hash of the password.
| username | password |
|---|---|
| john | 3729ad9ab30ed75be1f22a5f250f07ac |
Now, even if we see this table, it would be impossible for us to find out the original password from this hash. Now, if we want to log a user in, we have to hash the entered password and compare it to the hash in the table.
The problem : Turns out people are more similar than you think, and as a result you will find many passwords which are just common words and phrases. Many websites like this one have lookup tables of md5 hashes of common words. This means that if your user set a common word as his password, it can be easily looked up and cracked.
To prove my point, here are some md5 hashes of common words :
- lettuce : 8cbd191432b5f52b48497313f966a4f8
- cat : d077f244def8a70e5ea758bd8352fcd8
- bottle : 3a385ac07dcec4dde1a4ca47a9802c96
You can go here and enter these hashes to reverse them, proving that using one-way hashing alone is not enough.
One Way Hashing with Salt
We know that look up tables exist for common words, and we also know that we can’t trust our users to not use common words.
Many websites try to prevent this by forcing users to enter a combination of letters, numbers and special characters (which can get a bit annoying). A better alternative is to salt the users password.
“Salting” means to add a random string of letters and numbers to a users password, and then hash it. This more or less guarantees that the word is unique, and therefore cannot be part of a lookup table.

The final output you see has two $ symbols, between which the salt used to generate the rest of the hash lies. This is so that we can compare this hash with a user entered password.
If a user enters a password on login, we can validate it by following these steps:
- Get the hashed+salted password from our data store
- Read the salt from the stored data (the part between the $ symbols)
- Append the salt to the entered password, and hash the result
- Compare the output of this hash to the part on the right of the second $ symbol
You now have a secure form of password storage. Now no one, not even you, can ever find out your users passwords.
Note : this is also why almost all websites ask you to reset or create a new password, rather than reveal the password to you directly.
The next method is a repeated version of hashing and salting:
Repeated Hashing
Remember what we did in method #4? Now, take the result, perform method #4 on it… now take that result and perform method #4 on it again, and again.
Normally this is done an arbitrary number of times. If you thought reversing a hash is hard, try doing it many times over!
The steps to compare two passwords involves repeatedly hashing the entered password the same number of times and comparing the result to the stored hash.
Implementing Secure Password Storage
There’s a wise saying that most people should never implement their own encryption algorithms. There are many widely available algorithms that can implement hashing and salting.
Bcrypt is a good example of such an algorithm. It also has implementations and libraries in most programming languages.
You can read my post on password authentication and storage in Go if you want to learn how to implement this in practice.
Cross Site Scripting (XSS)
XSS attacks are one one of the most common form of attacks, and are often the starting point for many attackers looking to compromise your website.
The best way to explain XSS is to dive right into an example. Consider this HTML element :
<div id="status">
I am feeling alright
</div>Let’s assume this div is used to show your status on a popular social media site. It will be seen by many of your friends on their news feed and be seen as : “I am feeling alright”.
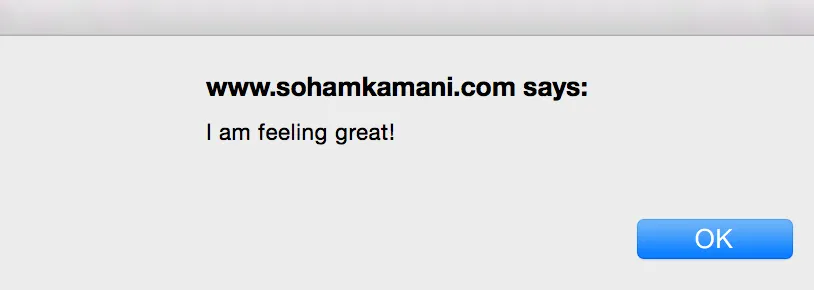
As a user, you can update your status to whatever you want, and it will appear inside this div element. If you were a malicious user, you could change your status from “I am feeling alright” to “<script>alert(‘I am feeling great!’)</script>”.
Your friends, however, would not see your status as “<script>alert(‘I am feeling great!’)</script>”, but instead, get an alert message which would look something like this :
This is because the text you just put in is rendered to HTML by default, which will make the content inside the div look like this :
<div id="status">
<script>
alert('I am feeling great!')
</script>
</div>Everything inside the script tag is considered javascript code and executed. So everyone across the site has this script executed, and the attacker has now compromised the behavior of the site.
Although this was a mild example, there are a lot more serious things that can be done this way, like submitting a form on someone elses behalf.
Preventing XSS
Make sure all information being rendered on the browser is HTML encoded first. This means converting some special characters to their HTML encoded equivalents first.
There are several ways to implement HTML character encoding, and many popular web frameworks support this out of the box.
Cross Site Request Forgery (CSRF)
Cross site request forgery (CSRF or XSRF), is a type of attack where a request coming from one website is disguised so as to give the impression that it’s coming from another. This attack is especially deadly as it can go completely unnoticed by a user, and even by the server being targeted.
This section explains what causes CSRF attacks, and what you can do to prevent them as a developer.
So what exactly is CSRF? It’s all in the name :
- Request forgery : Sending a request which appears to be legitimate but is actually malicious.
- Cross site : coming from a site other than the one for which it is intended.
But how can these other sites send such a request, and how can it be forged to appear like a legitimate request? The answer lies in the design of web browsers and how they send requests.
Consider two websites : a not-so-innocent news website (lets call it sillyfakenews.com), and your go-to social media portal (lets call it facehook.com).
Let’s say you’re already logged in to facehook.com, on another tab in your browser. One of the many posts you see on it includes a link to sillyfakenews.com, and since it looks interesting you open it in another tab, while still logged into facehook.
It turns out that sillyfakenews.com, along with showing you news, is also trying to compromise your facehook account. It sends a POST request to facehook to unfriend a few people on your friend list (This can be done very easily by using HTML forms and a bit of javascript.
Any website can actually make an invisible form and even submit it on your behalf, without you ever having to click a button. Check out the input hidden field to see how).
Now, since you already have an active session with facehook on the same browser ,and most likely have session information stored in the form of cookies, all this information is now sent along with the forged request. According to the facehook server, it’s as if this request was sent from the user while browsing on their site itself, and is therefore treated as a legitimate request.
The way browsers are designed, any request made from any site is treated the same with respect to cookies. This is why even though the request to facehook is sent from sillyfakenews.com, all the cookies associated with the current logged in session in facehook.com are sent as well.

Preventing CSRF
There are a couple of measures you can take to ensure that these attacks don’t take place with users on your site.
The most straightforward method is to block HTTP requests coming from other websites on the browser. Most popular browsers respect the “same origin policy” where by default (or if the server specifies it) requests going out from an origin other than the one the current site is being served from are prevented from going through by the browser.
Since this is something a browser respects, CSRF would still be a legitimate security concern if our user was using a browser that didn’t enforce the same origin policy. We can take other measures for these cases:
CSRF Tokens
This is the most popular method to counter CSRF attacks. With every session the user is on, a unique CSRF token is issued. This token is a bunch of random characters that cannot be predicted by any potential adversary.
Every time the client makes a request, the CSRF token is embedded in one of the response fields (most of the times in the request header). This token is then verified on the server.
This way, even if another site sends a malicious request with the cookies from facehook.com, the request still won’t contain the CSRF token, and so will not be entertained by the server.
SQL Injection
Modern databases have lots of security features to prevent them from being compromised by an attacker. However, even with the most secure database, there is still a way to compromise it right from the browser!
This section will explain why SQL injection occurs and how you can prevent it.
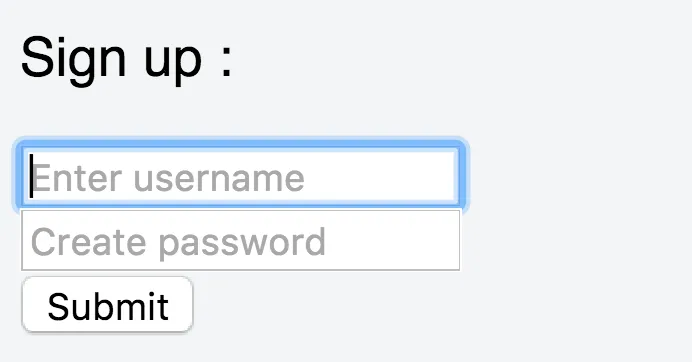
Let’s assume there’s a simple form on your website to sign up a new user.
Now as soon as you sign up a new user, you have to create a new entry in the database.
From the backend, the database query would look something like :
INSERT INTO `users` (username, password) VALUES ('<username>', '<password>');What you would now do is replace <username> and <password> with the values entered in our sign up form. So, if I entered my username as John Doe, and password as j0hnd03, my insert query would like :
INSERT INTO `users` (username, password) VALUES ('John Doe', 'j0hnd03');Normally, this would work just fine. But what happens if I change my username to ','');DROP TABLE `users`;-- ?
Once we insert this username into our query, it turns into :
INSERT INTO `users` (username, password) VALUES ('','');DROP TABLE `users`;--', '<password>');Let’s describe what happened here: It turns out, that this query recognizes special characters like ` , " , or - as part of the query, and not as part of the input parameters.
Since we are naively concatenating the entered username and password to generate our query, we don’t exactly have a way to tell our query that these special characters should be a part of the username, and not a part of the query.
The result, as expected, is disastrous. In this case, it leads to our entire users table being dropped.
Preventing SQL Injection
Make sure you always escape all your SQL queries! This means replacing special characters like ` , " with their escaped versions (i.e \` and \")
This is actually easier said than done, considering larger projects often have hundreds of queries with even more parameters to take care of, and it’s often impossible to make sure everything is escaped. The solution?
Use an ORM instead of writing your own queries. ORMs like this one for python, or this one for NodeJs make sure that your queries are safe, even if you have a lot of questionable characters in your input parameters.
Cross Origin Resource Sharing (CORS)
CORS, or cross origin resource sharing, is one of the most misunderstood concepts of web security. Many know what it is, some know why we need it, and only a few know its limitations.
This section will go through some of the key concepts of CORS, and emphasize why we need it for the modern web.
The best way to explain it is through an example.
First, Open up your browser, and navigate to stackoverflow.com.
Next, open up your browsers console, and run this snippet :
fetch('http://stackoverflow.com').then(res => console.log(res))You should see this nice clean response returned back, like this :

When executing the javascript code, we used the browsers fetch API to get the content of StackOverflow’s webpage, by making an http request. Now, lets try getting Wikipedia’s homepage instead :
fetch('http://wikipedia.org').then(res => console.log(res))If you run this code, you should see an error:

It looks like we’re not allowed to get the details of wikipedias homepage.
In fact, if you make a request to any origin other than StackOverflow, you will see this error. However, if you open your console on any wikipedia page , and make a request for Wikipedia’s homepage, you would get a good response once again.
To put it simply, it is forbidden to make a request to any origin, other than the one your code is running in, unless otherwise allowed by its server. This is called the same origin policy.
Almost all urls serving their resources will have a CORS policy. By default, if there is no policy, it is assumed that CORS is disabled.
But why? It might seem harmless to allow requests to another origin. After all, that url would receive millions of other requests from unknown sources anyways. The answer lies in the way browsers work.
All requests sent from your browser are treated the same. The server receiving them cannot distinguish the circumstances under which they were sent.
This means that if you were logged in on one site, and browsing another (malicious) site, an http request made by that sites to the first site, would be treated as a genuine request from you.
This means that this :

Could turn into this :

CORS Policy Enforcement
This is often the most misunderstood aspect of CORS. It’s quite contradictory that one cannot make a simple http request from their own browser to a different origin, but you can make the same request using something like postman or curl from the command line.
If these kind of requests cannot be made from the browser, how are they so easily made through these third party applications, which can be equally as malicious?
CORS isn’t actually enforced by the server, but rather the browser. The server simply states the sites that are allowed cross origin access through the Access-Control-Allow-Origin header in all its responses. It is up to the browser to respect this policy.
Of course, all popular browsers in use today do follow the same origin policy. Some applications like postman, curl do not respect this policy, because they are meant to be used as developer tools.

Caveats and Exceptions
1.Fetch can make cross origin requests : There is a no-cors mode that can be made use of to make cross origin requests with fetch, like this
fetch('http://wikipedia.org', {
mode: 'no-cors'
}).then(res => console.log(res))However, you won’t be able to read this response for the same reasons as before. This is only useful if you want to do things like response forwarding.
2.CORS can be stricter than usual : The above comic is not always true. If a server really does not want other clients to receive a response, it can disable CORS for non browser clients as well. This means that you can only make requests from the same origin, and that tools like postman and curl can’t make requests either.
Wrapping Up
We’ve looked at several types of common attacks and measures to prevent them.
However, this is just the tip of the iceberg. This post was intended to help you get started with the basics, but you should be aware that this is an ever-evolving topic, and keep yourself updated.
The OWASP web security testing guide is a great place to start.