Table of Contents
If you’re a Java developer and want to know how to use the latest Gemini model in your application, this post is for you.
In this post, we’ll cover how to set up a Google Cloud project and call the Gemini API from your Java application.
If you just want to see the code, you can skip to the Adding the Gemini API to Your Java Application section, or you can see the full code on GitHub.
What Is Gemini?
Gemini is a powerful AI model from Google DeepMind that excels in various tasks like text generation, translation, coding, and more.
If you want to try out Gemini now, you can go to gemini.google.com to see how it works.

Anyone can chat with Gemini for free, but if you want to use it in your application, you need a Google Cloud project — so let’s set that up first.
Setting up Your Google Cloud Project
If you’re able to access this page and chat with the model, you can skip this section.
First, create a new project on the Google Cloud Console.
Once you have a project, you’ll need to:
- Enable billing for your project.
- Enable the Vertex AI API.
- Install the gcloud CLI tool.
Once you’ve done all that, you should be able to to access Vertex language page:
Creating and Testing Prompts
You can create and test prompts on the Vertex language page. It’s good to test a wide range of prompts for your use case to see how the model responds.
You can also choose the model and temperature and see how the response changes. (We’ll discuss more about this in the next section.)
For example, if you want to make an application that generates stories, you can test prompts like:
“Write a short story about a robot who learns to love the smell of freshly baked bread. Make sure it’s funny and heartwarming.”
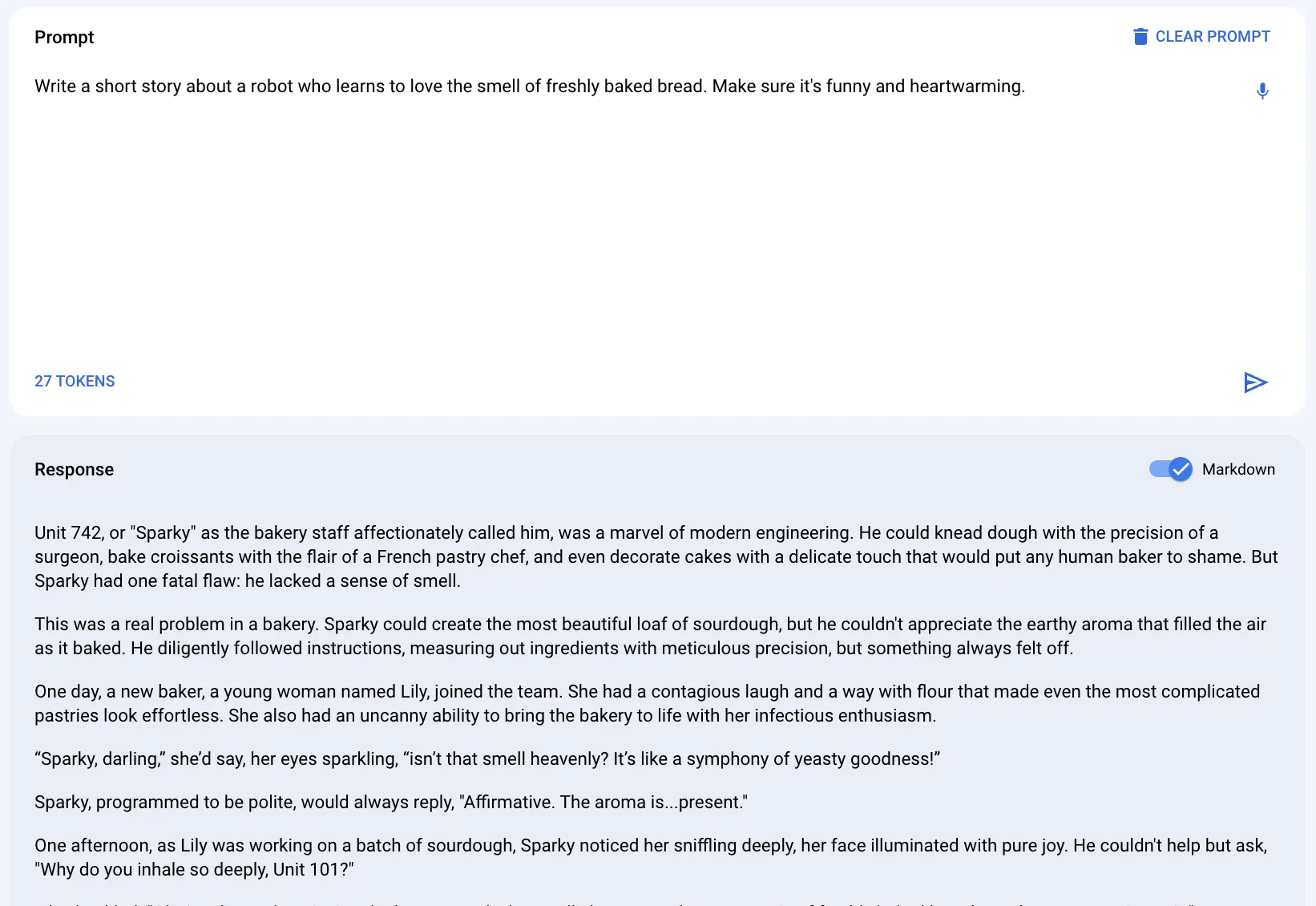
Once you’re happy with the prompt, we can add it to our Java application.
Adding the Gemini API to Your Java Application
You can export the prompt from the Vertex language page by clicking on the “GET CODE” button:
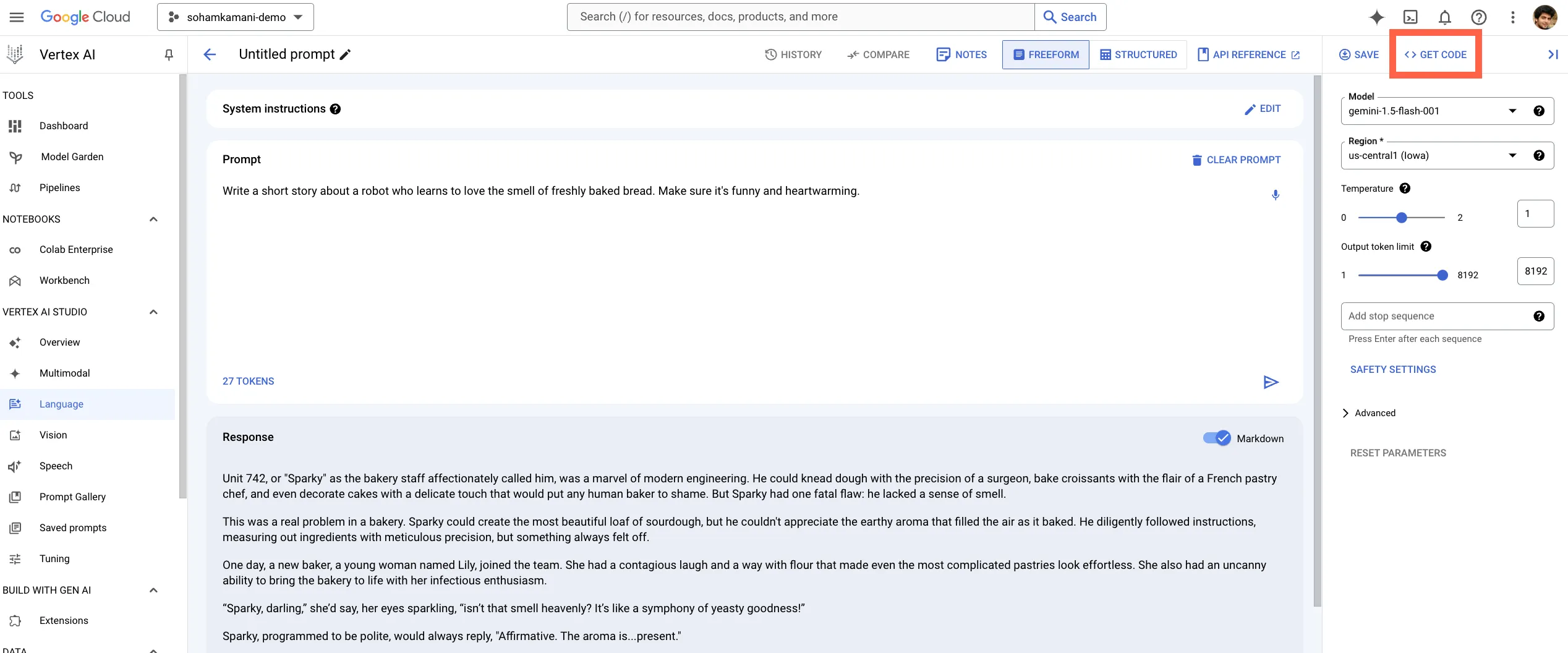
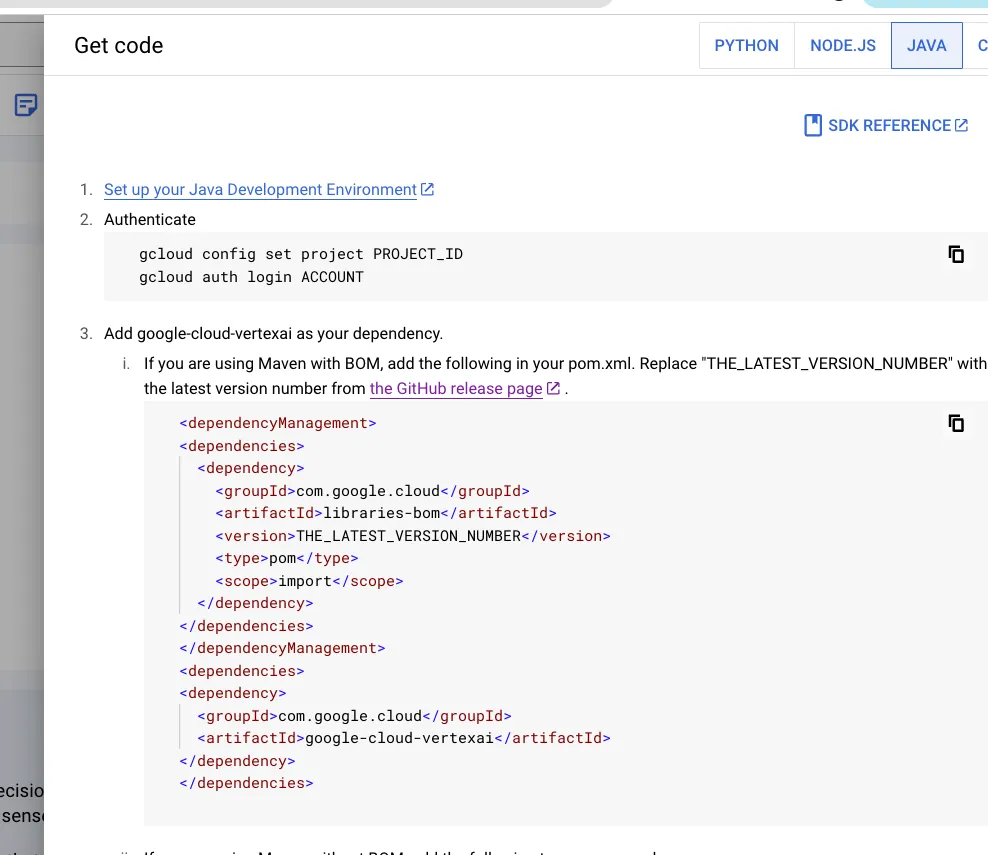
Then, click on the Java tab, which will give you instructions on how to use the Gemini API in your Java application:
Now, let’s go to our Java application. We’ll use a standard Maven project for this example.
As mentioned in the instructions, you need to install the dependencies and add the code that you got from Vertex Studio.
First, we can add the dependencies to our pom.xml file:
[...]
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.43.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vertexai</artifactId>
</dependency>
</dependencies>
[...]Next, we can add the code that we got from Vertex Studio to our Java application:
package com.sohamkamani;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import com.google.cloud.vertexai.VertexAI;
import com.google.cloud.vertexai.api.GenerateContentResponse;
import com.google.cloud.vertexai.api.GenerationConfig;
import com.google.cloud.vertexai.api.HarmCategory;
import com.google.cloud.vertexai.api.SafetySetting;
import com.google.cloud.vertexai.generativeai.ContentMaker;
import com.google.cloud.vertexai.generativeai.GenerativeModel;
import com.google.cloud.vertexai.generativeai.ResponseStream;
public class App {
public static void main(String[] args) throws IOException {
try (VertexAI vertexAi = new VertexAI("sohamkamani-demo", "us-central1");) {
GenerationConfig generationConfig =
GenerationConfig.newBuilder()
.setMaxOutputTokens(8192)
.setTemperature(1F)
.setTopP(0.95F)
.build();
List<SafetySetting> safetySettings = Arrays.asList(
SafetySetting.newBuilder()
.setCategory(HarmCategory.HARM_CATEGORY_HATE_SPEECH)
.setThreshold(SafetySetting.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE)
.build(),
SafetySetting.newBuilder()
.setCategory(HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT)
.setThreshold(SafetySetting.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE)
.build(),
SafetySetting.newBuilder()
.setCategory(HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT)
.setThreshold(SafetySetting.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE)
.build(),
SafetySetting.newBuilder()
.setCategory(HarmCategory.HARM_CATEGORY_HARASSMENT)
.setThreshold(SafetySetting.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE)
.build());
GenerativeModel model =
new GenerativeModel.Builder()
.setModelName("gemini-1.5-flash-001")
.setVertexAi(vertexAi)
.setGenerationConfig(generationConfig)
.setSafetySettings(safetySettings)
.build();
var content = ContentMaker.fromMultiModalData("hey");
ResponseStream<GenerateContentResponse> responseStream =
model.generateContentStream(content);
// Do something with the response
responseStream.stream().forEach(System.out::println);
}
}
}Note: You don’t need to copy the code line by line. You can copy the part within the
mainfunction on the Vertex instruction page and paste it into your Java application.
Let’s run the application and see the response:
mvn exec:java -Dexec.mainClass="com.sohamkamani.App" -Dexec.classpathScope=runtimeIf you run this, you should see the live response from the Gemini model:
candidates {
content {
role: "model"
parts {
text: "Bar"
}
}
}
candidates {
content {
role: "model"
parts {
text: "tholomew was not programmed for emotions. He was a glorified toaster, a"
}
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
probability_score: 0.25
severity: HARM_SEVERITY_NEGLIGIBLE
severity_score: 0.11279297
}
}
candidates {
content {
role: "model"
parts {
text: " sentient waffle iron, a robot designed to make breakfast, nothing more. His days"
}
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLEMost of the time, the response will be broken down into multiple parts, and each part will have a safety rating, and the partial text generated by the model (See candidates --> content --> parts --> text).
The default code provided by Vertex uses a response stream, which gives you the response in real time, part-by-part. This is useful if you want to show the response to the user as it comes in, as fast as possible.
If you want to wait for the entire response to come in before processing it, you can use the genetateContent method instead of generateContentStream:
[...]
var text1 =
"Write a short story about a robot who learns to love the smell of freshly baked bread. Make sure it's funny and heartwarming.";
var content = ContentMaker.fromMultiModalData(text1);
GenerateContentResponse response =
model.generateContent(content);
System.out.println("Response:" + response);This will give you the entire response in one go:
Response:candidates {
content {
role: "model"
parts {
text: "Bender was a very good robot. He could fold laundry with precision, vacuum without a single missed spot, and even make a mean cup of coffee. But Bender had a problem. He couldn\'t smell. He was
...........<truncated>...........
tune, his sensors rejoicing in the warmth and the fragrance that filled the air. He may not have been able to understand the magic of baking, but he knew it was magic nonetheless, a magic that had touched his robotic soul. \n"
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
probability_score: 0.06933594
severity: HARM_SEVERITY_NEGLIGIBLE
severity_score: 0.09277344
}
}
usage_metadata {
prompt_token_count: 27
candidates_token_count: 698
total_token_count: 725
}Here, candidates --> content --> parts --> text contains the entire response generated by the model.
You can see the full code on GitHub.
Changing Model Parameters
To get the best possible response from the model, its best to play around with the model parameters, until the responses align with what you want.
The different options we have here are:
-
Model Type: The model type is the version of the Gemini model that you want to use. Different models have different response times and capabilities.
For example, the
gemini-1.5-flashmodel is a fast model that can generate responses quickly, but it may not be as accurate as thegemini-1.5-promodel, which is slower but more accurate. -
Temperature: The temperature parameter controls the randomness of the response. A higher temperature will give you more creative responses, so if you need a creative story, you can increase the temperature.
A lower temperature will give you more predictable responses, which is useful if you want to generate factual information or want the response to retain the same tone from one prompt to the next.
Grounding Responses
Language models are known to generate responses that are hallucinated, or not grounded in reality. This is because the model is trained on a large corpus of text, and it doesn’t have a real-world understanding of the text it generates.
This could mean disaster if you want to use the model to generate factual information.
To fix this, Vertex allows you to “ground” the responses, which means that the model will consult a real-world data source (like Google search) to produce its final response.
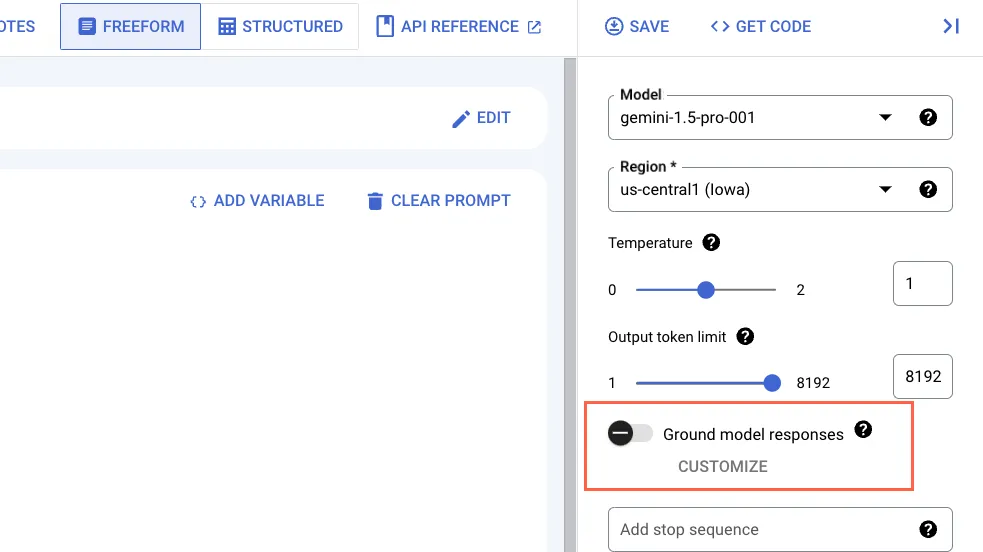
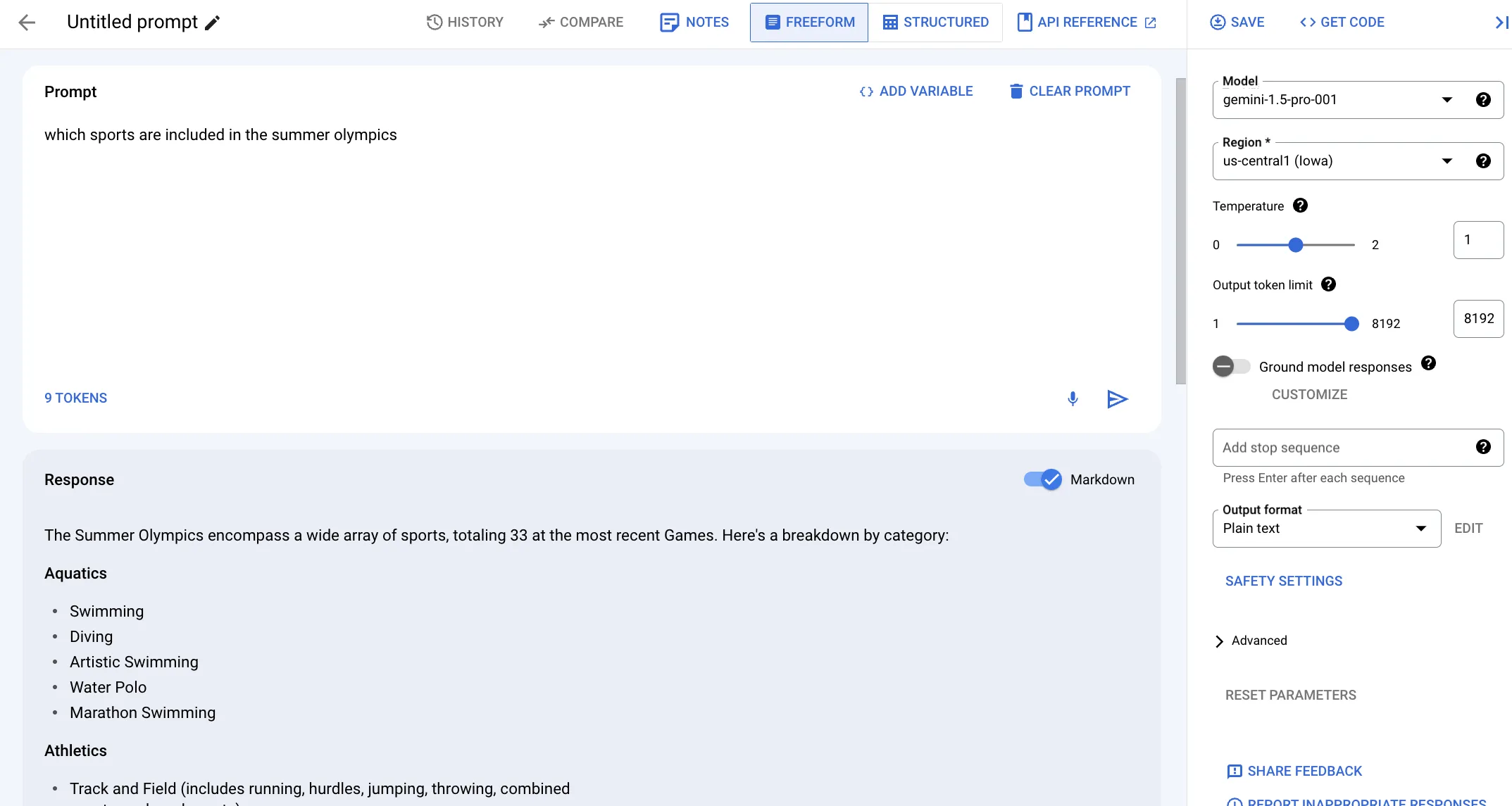
Let’s see how this works, by giving a prompt that requires factual information:
which sports are included in the summer olympicsWithout grounding, we get a generic response of sports that are generally included in the summer olympic games:
But when we use grounding, the model consults Google search to get the most up-to-date information:
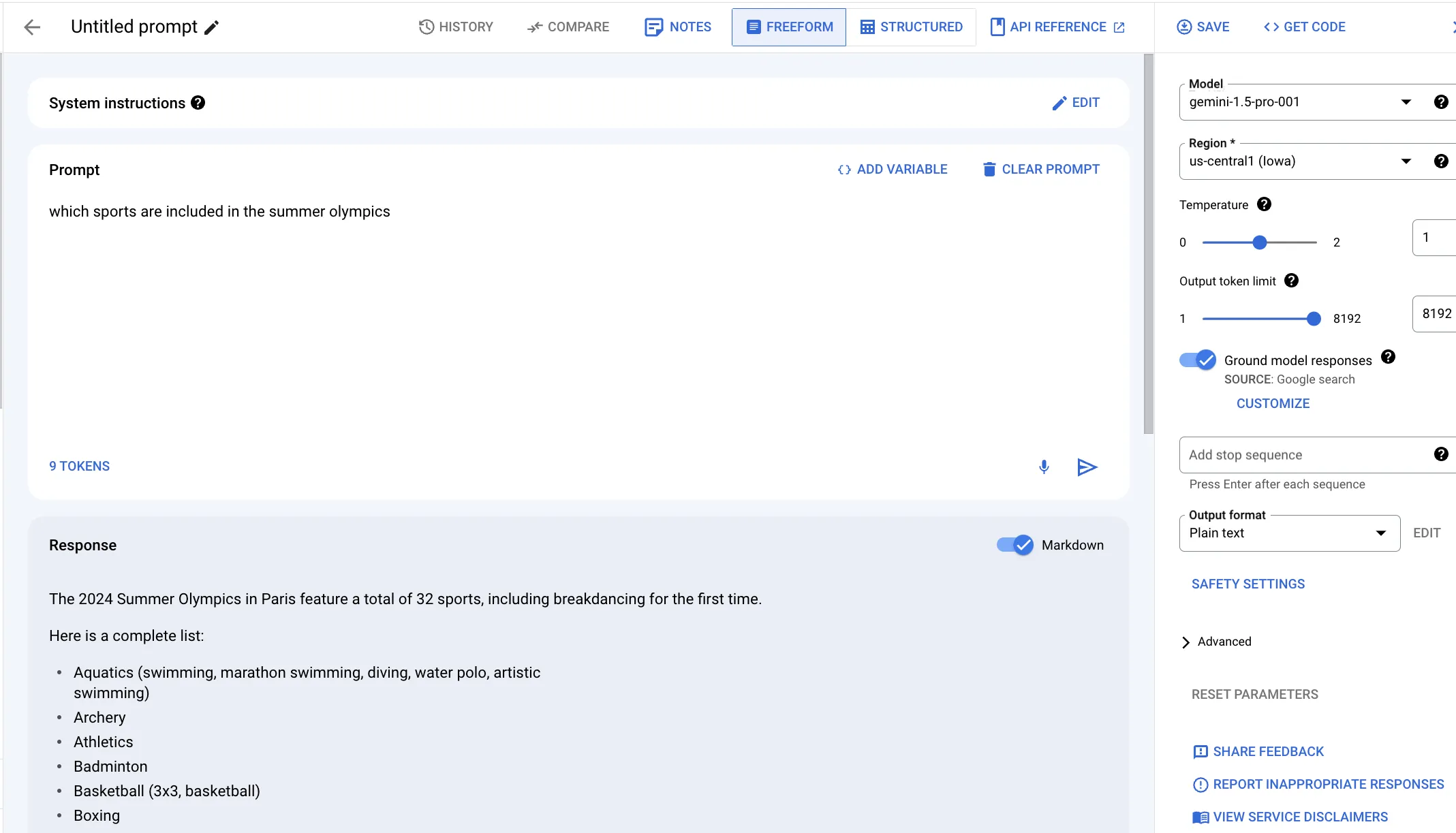
Now, the answer is more specific and up-to-date, and specifically mentions the 2024 olympics in Paris, as well as the newest inclusion of break-dancing.
Caveat: adding grounding can increase the overall cost, and you don’t need to use grounding for all prompts — only for those that require factual information. For example, if you want to generate a fictional story, or if you only want to change the tone or presentation of some input text, you don’t need to use grounding.
Further Reading
The available models are constantly changing, so it’s a good idea to check the official documentation for the latest models available and their recommended use cases.
If you need help with structuring your prompt itself, you can see the Generative AI prompt samples that have examples for several use cases.