Table of Contents
Monitoring an application’s health is one of the most important tasks when running production grade services.
The standard way to do this is to periodically check the “heartbeat” of a running application by interacting with one of its API endpoints.
Although this method can tell you if the application itself is up and running, it doesn’t tell you anything about the many services that the application depends on (for example, a database, cache, or another running service), even though these dependencies are critical for its functioning.
This post elucidates the limitations of current monitoring techniques, and introduces a composable method of checking the health of an application together with the services that it depends on.
The current state of application health checks
The most common way of running application health checks is by routinely interacting with a “ping” endpoint. This is an extra endpoint added to a service for the sole purpose of expressing its availability.
If the service happens to be an HTTP server, then the ping endpoint would probably refer to an HTTP GET call to a /ping route:
curl -X GET http://your_service_url.com/pingThis is a pretty good way of checking if a service is running or not. In real world applications though, a service always uses other services to function. This can be anything from a database, to another HTTP server.

The limitation of using the ping endpoint for checking the health of an application in this context, is that it can only tell you if the application itself is alive. It does not reveal anything about the state of its dependencies.
If a dependency is critical for the functioning of any service, then it should be considered while monitoring the health of an application. In the above example, even though the database is necessary for the functioning of the HTTP application, the health check will return a positive result if the database fails. This is because the ping endpoint does not take the state of the applications dependencies into account.

The dependent ping endpoint
To have the ping endpoint better represent the health of a running application, it should be dependent on the same set of services that the application itself depends on. This can be realized if the ping endpoint itself checks the ping endpoints of the applications dependencies

With this setup, the applications ping endpoint would return an error state if any of the dependent ping endpoints return an error.

Composing additional applications
The dependent ping endpoint is a simple concept, but with a bit of standardization, we can use it along with other dependent ping endpoints to create a composable framework for monitoring the state of an applications entire dependency tree.
First, let’s define a couple of terms to paint a better picture:
- An Endpoint is any applications ping endpoint that informs you about its health. The “HTTP Application” was the endpoint in the above examples.
- A Dependency is any service that an endpoint checks in order to determine its health. The “Database”, “Cache” and “Other HTTP application” were dependencies in the above example.
- Each endpoint and dependency have a State - which is the bundled information that tells you about their health.
- An endpoint can contain dependencies
- An endpoint can be a dependency itself
With an endpoint itself being a dependency, we can compose a chain of endpoints that each have their own dependencies. This is actually how many service based architectures are organized.

If we use the dependent ping endpoint described in the last section, this means that pinging “Endpoint 1” would end up pinging the entire dependency tree.

This now changes the purpose of an applications ping endpoint from answering “Is my server running?” to “Is my service, and all its dependencies, healthy?”, which is much more meaningful.
Practical implementation
Implementing these concepts isn’t very hard, but if you need to get up and running quickly, I’ve released the Detective, a library that lets you make composable ping endpoints, and add them to your application in a non-intrusive way.
Currently, Detective is implemented in Go and Node.js.
It allows you to create arbitrary dependencies, and create a ping endpoint that checks their state every time it’s called:
// Initialize a new detective instance
d := detective.New("Another application")
// Create a dependency, and register its detector function
d.Dependency("cache").Detect(func() error {
err := cache.Ping()
return err
})
// Create an HTTP endpoint for health checks
http.ListenAndServe(":8081", d)It’s also possible to compose additional endpoints and add them to an existing instance:
// Create a new detective instance
d2 := detective.New("your application")
// Add an endpoint, which represents another detective instance
// (which is running on port 8081 in the previous code snippet)
d2.Endpoint("http://localhost:8081/")
http.ListenAndServe(":8080", d2)Once you have a detective-enhanced ping endpoint running, you can use the dashboard to view your entire dependency tree, it’s latencies and its overall state:
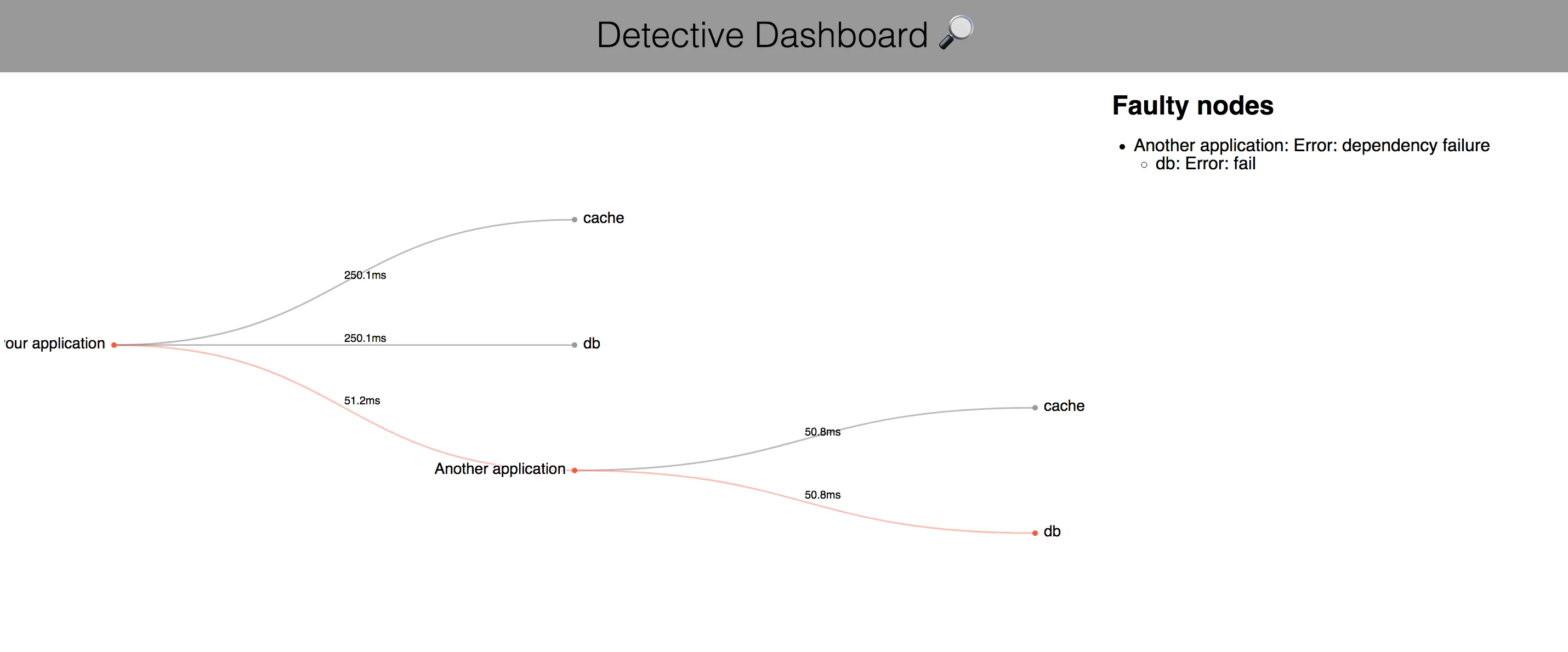
Conclusion
Most service based architectures today emphasize small independently running services that depend on each other to make the entire application work. To accurately ascertain the health of the system, the monitoring framework should also follow a similar process.
Dependent ping endpoints help us monitor our application better, because they closely mimic the way the actual application works, and therefore add value to the existing checks that are in place.